
Los modelos de lenguaje generativos, y en especial ChatGPT, han tenido un gran impacto en la ciencia y la sociedad1,2. Aunque la inteligencia artificial (IA) ha logrado avances significativos en la detección de plagios y la selección de estudios para revisiones sistemáticas3, no se ha explorado su posible aplicación a la revisión científica por pares. La revisión por pares es un proceso que requiere muchos recursos tanto económicos como de esfuerzo humano, y es posible que pueda beneficiarse de la eficiencia de la IA en cuanto a la rapidez del procesamiento de datos, la exactitud y la capacidad de síntesis de cantidades enormes de información. En este estudio se evaluó la capacidad de ChatGPT de generar revisiones científicas válidas en cardiología en comparación con expertos humanos.
Se incluyeron en el estudio cartas científicas consecutivas entre mayo de 2022 y mayo de 2023 que fueron objeto de una revisión por pares en la Revista Española de Cardiología(Rev Esp Cardiol), que es el órgano científico oficial de la Sociedad Española de Cardiología, fundada en 1947, y se encuentra en el primer cuartil de las revistas cardiovasculares en el Journal Citation Reports de 20224,5. Se excluyeron los artículos originales y las revisiones, ya que superaban la máxima extensión de texto para ChatGPT. De cada carta científica, se generó una revisión con el modelo de ChatGPT (RGPT). Mediante pruebas iterativas con cartas científicas publicadas, se elaboró un prompt (indicación) específico para orientar las respuestas de ChatGPT en la revisión de cartas científicas. Este prompt se afinó según las normas de Rev Esp Cardiol y se utilizó para generar todas las RGPT. Se utilizó la interfaz de programación de aplicaciones Application Programming Interface con el modelo «gpt-4-0613».
Los editores asociados de Rev Esp Cardiol (P. Avanzas, D. Filgueiras-Rama, P. García-Pavía y L. Sanchis) y su editor jefe (J. Sanchis) revisaron la calidad de la RGPT y la revisión humana (RH). El proceso de revisión estándar para las cartas científicas en Rev Esp Cardiol incluye la participación de 2 revisores, y el editor asociado encargado de la carta asigna una puntuación de 0 a 100 a la calidad general. Se tomó como RH la del elegido como revisor número 1 durante el proceso estándar de revisión. El mismo editor que había gestionado inicialmente el manuscrito durante el proceso de revisión estándar evaluó también la calidad general de la RGPT, y le asignó una puntuación de 0 a 100. Un segundo editor elegido de manera aleatoria evaluó la RH y la RGPT utilizando un diseño con enmascaramiento. Para este fin, la RH y la RGPT se presentaron en un orden aleatorio, anonimizadas y designadas como «Respuesta1» o «Respuesta2» para la carta científica. El segundo editor analizó los siguientes dominios: calidad de la información, calidad de la redacción y juicio crítico, y asignó una puntuación de 0 a 100 a cada dominio. Se pidió también a los editores que adivinaran qué revisión era la RH y cuál la RGPT y determinaran cuál era mejor.
Se utilizó una prueba de la t de Student para muestras independientes para comparar las puntuaciones medias de calidad de la RH y la RGPT y la prueba de la χ2 para las variables cualitativas. El objetivo elegido para estimar el tamaño de la muestra fue la preferencia de revisión (RGPT o RH) elegida por el editor. Partiendo del supuesto de un riesgo alfa de 0,05 y un riesgo beta de 0,2 en un contraste bilateral, se necesita un mínimo de 48 pares de respuestas (cada uno formado por una RGPT y una RH) para detectar una diferencia del 20% en la preferencia de respuesta, suponiendo unas preferencias del 65 frente al 45% por la RH frente a la RGPT. El estudio se llevó a cabo según lo indicado en la edición más reciente de las recomendaciones del Comité Internacional de Editores de Revistas Médicas6.
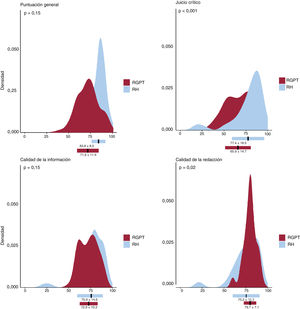
Se seleccionaron inicialmente las 85 cartas científicas recibidas en Rev Esp Cardiol durante el periodo de estudio y se les aplicó la revisión por pares. Se excluyeron 10 cartas (11,7%) porque se habían enviado y revisado inicialmente en forma de artículos originales. En estos casos se ofreció a los autores la posibilidad de convertir sus artículos en cartas científicas tras el proceso de revisión. En consecuencia, se incluyeron en el análisis 75 cartas científicas. Se enviaron a ChatGPT un total de 911.907 tokens (unidades o elementos de texto), de los cuales 483.681 fueron completion tokens (tokens de finalización o de completado), que generaron 75 RGPT con un coste de 56,38 dólares (0,66 dólares por revisión). La RH obtuvo una puntuación general media mejor que la RGPT en la evaluación realizada por el editor original sin enmascaramiento (83,8±8,8 frente a 71,6±11,9 puntos; p<0,001) (figura 1). Hubo una mala correlación entre las 2 evaluaciones (r=0,209; p=0,079).

La evaluación del editor con enmascaramiento mostró que las calidades de la información de la RGPT y la RH eran similares (72,9±10,3 frente a 75,9±14,6 puntos; p=0,15; la RGPT fue mejor en 32 [43%] de las cartas). La RGPT obtuvo una puntuación más alta en cuanto a la calidad de la redacción (79,6±7,1 frente a 75,2±15,3 puntos; p=0,02; la RGPT fue mejor en 51 [68%] de las cartas), mientras que la RH mostró un mejor juicio crítico (65,87±14,69 frente a 77,4±18,5 puntos; p<0,001; la RGPT fue mejor en 21 [28%] de las cartas) (figura 1). En las evaluaciones de la RH hubo más valores atípicos, mientras que las evaluaciones de la RGPT fueron más homogéneas (figura 1). El editor determinó correctamente si la revisión era la RGPT o la RH en la mayor parte de los casos (n=74, 99%). Es interesante señalar que la RGPT se consideró mejor que la RH en 27 casos (36%).
En este estudio se evalúa la calidad de un modelo de lenguaje natural generativo para revisiones editoriales científicas en cardiología y se compara con la de las RH. Se observa que la RH proporciona una mejor revisión general, en especial en el dominio del juicio crítico. Sin embargo, la RGPT se considera mejor en alrededor de una tercera parte de las cartas y obtiene unas puntuaciones de calidad más homogéneas. En cambio, la calidad de la RH muestra una mayor dispersión como resultado de la mala calidad de algunas revisiones. De hecho, encontrar buenos revisores hoy es un verdadero reto. Nuestros resultados podrían ser de interés en una época en la que, mientras la IA se aplica cada vez más en diferentes campos, las publicaciones científicas están aumentando exponencialmente, y la evaluación científica está pasando a ser cara y problemática. La calidad de la información fue similar, pero la RGPT mostró una mejor calidad de redacción, lo cual puede atribuirse a la capacidad del modelo de generar respuestas bien estructuradas utilizando grandes cantidades de datos previos6. La RH superó a la RGPT en juicio crítico, probablemente por la experiencia, la intuición y el conocimiento experto especializado de los humanos. A pesar de su carácter experto en el análisis de patrones de datos, la RGPT carece de un discernimiento matizado. Esto subraya que el análisis humano es irreemplazable en contextos que requieren juicio crítico. No obstante, ChatGPT-4 podría usarse como instrumento de cribado inicial en el proceso de la revisión por pares y podría ayudar a los revisores a organizar y redactar mejor sus evaluaciones.
Las limitaciones de este estudio son: a) su carácter retrospectivo; b) se centra únicamente en una revista, Rev Esp Cardiol, lo cual podría limitar la posibilidad de generalizar los resultados a otras publicaciones y otros campos, y c) la evaluación solo de cartas científicas, no de artículos originales, que podría limitar los resultados debido a las diferencias de formato y profundidad del contenido entre estos tipos de artículos.
En resumen, las preocupaciones planteadas por los organismos de financiación acerca de la confidencialidad y la originalidad de las revisiones por pares generadas mediante IA subrayan la necesidad de salvaguardas éticas y metodológicas. En nuestra opinión, la IA podía ser útil en el proceso de revisión al resumir el contenido del artículo y ayudar a los revisores a no pasar por alto información pertinente. Sin embargo, el juicio crítico y los pensamientos originales de los revisores son atributos únicos que resultan esenciales en una buena revisión.
FINANCIACIÓNNinguno.
CONSIDERACIONES ÉTICASEl trabajo no requirió aprobación del comité de ética. No se utilizaron datos de pacientes. No se consideró el sesgo de sexo y género, ya que no se analizaron el sexo ni el género.
DECLARACIÓN SOBRE EL USO DE INTELIGENCIA ARTIFICIALSe utilizó ChatGPT-4 para generar revisiones científicas como parte de la metodología de este trabajo.
CONTRIBUCIÓN DE LOS AUTORESTodos los autores participaron en el diseño del estudio. A. Fernández-Cisnal y J. Sanchis redactaron la versión preliminar del artículo. P. Avanzas, D. Filgueiras-Rama, P. Garcia-Pavia y L. Sanchis revisaron el artículo.
CONFLICTO DE INTERESESJ. Sanchis es editor jefe de Rev Esp Cardiol y P. Avanzas, D. Filgueiras-Rama, P. Garcia-Pavia y L. Sanchis son editores asociados de Rev Esp Cardiol. Se ha seguido el procedimiento editorial establecido por la Revista para garantizar un procesamiento imparcial del manuscrito. Los autores no tienen otros conflictos de intereses que declarar.
AGRADECIMIENTOSLos autores desean agradecer a la oficina editorial de Rev Esp Cardiol su trabajo de preparación de las cartas científicas.