There is no doubt that observational epidemiological studies have been enormously useful in the search for possible determining factors of disease and in the development of etiologic hypotheses. Historically, however, these studies have been criticized for their important limitations when establishing anything more than a simple association between the phenotype or exposure factor studied and the disease of interest.1
Some observational research articles in the medical literature report some degree of association between diverse factors (social, behavioral, environmental, nutritional, genetic, epigenetic, etc.) and different cardiovascular diseases. Many of these studies go unnoticed by the scientific community, mainly because their findings are isolated results that have not been reproduced or corroborated by other studies. Nonetheless, on other occasions, several independent research studies can reach the same conclusion, so that the degree of scientific evidence obtained is sufficient for the scientific community to consider human experimentation using randomized controlled trials (RCT), which are able to confirm whether observational findings are valid and infer causality.
Unfortunately, the associations proposed by some of these observational studies are frequently not confirmed by the results of RCT. This is generally due to the inability to rule out, on the one hand, the presence of confounding factors or variables that were unexpected or not measured and, on the other, the existence of an inverse causal relationship between the exposure and the outcome.1 Thus, despite the systematic use of adjustment methods (eg, multivariate analyses) used to try to control confounding factors in a given study, the more than likely existence of some type of bias (impeding control of residual confusion) does not allow causality to be inferred with any certainty. Another explanation for the apparent lack of agreement among results is that the research questions posed in observational studies and RCT are often different. This has generated an epidemiological focus that analyzes observational studies as if they were RCT.2
Randomized controlled trials are considered the gold standard since they provide the highest level of statistical evidence possible, making them the ideal study type to answer questions that may arise in clinical research. Nonetheless, despite all their advantages, the particular technical, ethical and economic circumstances specific to each research study and their individual procedures do not always allow the use of RCT.
MENDELIAN RANDOMIZATION ANALYSES: CONCEPTUAL AND METHODOLOGICAL FRAMEWORKMendelian randomization (MR) studies are considered a special case within a more extensive type of applied statistics, known as instrumental variables (IV). This type of analysis was developed for the social sciences (particularly econometrics), where they are usually used to estimate the impact of certain policies or social measures when it is not possible to implement an experimental design.3
These analyses are based on the identification of some type of variable natural phenomenon (known generically as IV or simply “instrumental”) used in the statistical analysis to adjust for possible confounding factors in the research study.
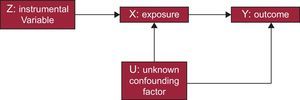
For these IV phenomena (variables or instruments) to be considered appropriate, they should agree with a series of premises. A common way to define and explain such conditions is through the use of DAG (directed acyclic graphs).4 These graphs are the basis of these studies and show the possible causal correlations of the variables contemplated in the study (Figure 1).

First, the variable should have a quantifiable relationship with the exposure of interest. Second, the variable cannot be directly related to the result or outcome of the intervention except through its correlation with the exposure itself. Third, the IV should be independent of possible unknown or uncontrollable confounding factors that may exist between the intervention and the outcome.5 If these requirements are met, IV analyses can confirm whether there is a causal relationship between an exposure (treatment or intervention) (eg, environmental contaminant or a medication) and a result (outcome) (eg, high blood pressure or myocardial infarction).
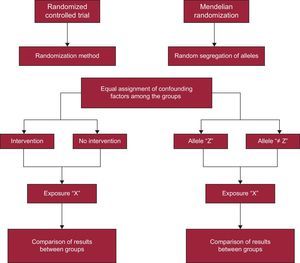
As previously mentioned, MR studies are a particular type of IV analysis. What characterizes these studies is the use of genetic variants such as IV for the analysis. Thus, in this case, the variable natural phenomenon chosen is a certain genetic polymorphism that is related to an exposure factor, a potential cause of a certain disease, or an outcome under study. This methodology is inspired by and based on Mendel's second law (law of independent assortment), which states that, save for exceptions (eg, the presence of genetic linkage or stratification in the population), the assortment of parental genes among gametes is random due to meiotic division of germ cells during gametogenesis.1 In other words, gene transfer from parent to child is a chance occurrence, similar to random assignment into the different experimental groups created for RCT. This circumstance has enabled MR studies to be equated with RCT,1 with the difference that MR study participants are randomly assigned to different genotypes instead of to different clinical trial groups (Figure 2).

As shown in Figure 2, MR studies are a nonexperimental alternative to RCT. In this case, the randomized assignment of individuals into groups does not depend on the researcher; instead, it is the independently inherited genes themselves that are used to create a statistical approach. That is, as shown in Figure 1, the instrument (Z) represents the treatment assignment, X is the treatment, and Y is the outcome of the trial (Figures 1 and 2).
As previously mentioned, these analyses are especially useful in observational epidemiological studies, where they allow a causal effect to be inferred, despite the existence of problems of unknown or unmeasurable confounding factors. Furthermore, their usefulness has also been verified by analysis of data from RCT. These studies do not present the limitations of observational studies because the randomization process divides any confounding factors equally between the experiment groups. Nonetheless, RTC are not free from complications, since trial volunteers often show problems of adherence or noncompliance with the treatment under study. Under these circumstances, it is recommended to analyze the data on an intention-to-treat (ITT) basis, which, even though it is the ideal option, can lead to biased results due to the aforementioned lack of treatment adherence.6
In an ITT analysis, the results obtained from the trial groups are compared without considering whether all the participants included in the analysis had really received the treatment. In this situation, ITT analysis does not estimate the effect of the treatment (intervention) on the outcome; instead, it actually estimates the effect of being assigned to receive treatment. Given this situation, IV analysis offers the possibility of truly estimating how the treatment affected the participants who received it.6
INSTRUMENTAL VARIABLES ESTIMATIONOver the years, several statistical methods have been developed to calculate IV estimators according to the particular circumstances of each analysis. When a binary instrument is available (eg, a gene with only 2 alleles), an IV estimator known as the Wald estimator is usually used.6 To obtain this estimator, the first step is to calculate the correlation between IV (Z) and the outcome variable (Y) (Figure 1), which in an RCT would be equivalent to the estimate of the ITT analysis (if an RCT is being analyzed, as previously discussed, Z equals the randomized assignment; therefore, the correlation between Z and Y corresponds to the estimate of the ITT analysis). This correlation is able to confirm whether there is a true causal relationship between the exposure variable (X) and Y. If exposure (X) has no effect on the result or outcome (Y), Z and Y are independent; likewise, if X affects Y, Z and Y are not independent. Nonetheless, the association between Z and Y is not as strong as the association between X and Z.
When estimating the effect of X on Y, it should be considered that Z does not perfectly determine X; therefore, the second step in this method entails recalculating the effect of Z on Y, based on the effect of Z on X. In this manner, the IV estimator is obtained, which is the ratio between the difference in Y according to the different values of Z and the difference in X according to the values of Z (equation 1):
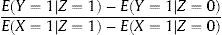
Considering that E(Y=1|Z=1) is defined as the mean value of Y among the study participants assigned to treatment Z=1, the calculated estimator will be sensitive to those patients who withdraw from or are lost to the trial. If all the volunteers complied with their assigned treatment, the IV estimate would be equal to the estimate obtained by the ITT analysis; nevertheless, as the number of withdrawals grows, this estimate becomes oversized in proportion to the number of the losses from the trial.
Moreover, in some situations, instruments with more than 2 values (eg, multiple polymorphisms) are available or there is a need for simultaneous adjustment by other covariables. In these circumstances, the 2-stage least squares estimator is usually used.6 Basically, this method is applied in the following manner: first, the adjusted values for the exposure variable (X) are obtained with a regression of that variable (X) on the IV (Z) and any known confounding variables (U). Thus, the predicted values of X are estimated depending on the adjustment made with the regression (equation 2a). Second, another regression is done with the outcome variable (Y) on the predicted values of X, which function as independent variables in the regression model (equation 2b). In this model, the coefficient of the predicted value of X (¿) (equation 2b) is interpreted as the estimate (by IV) of the effect of the exposure on the outcome:
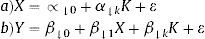
Given the introductory nature of this article, we recommend that readers consult other more specific publications as a source of further information on MR studies and estimation of odds ratios and relative risk, statistical power calculation, validation of premises, and 2-stage study designs.5–9
CONTRIBUTIONS OF MENDELIAN RANDOMIZATION TO CARDIOLOGY: IMPORTANT FINDINGS AND EXAMPLESIn recent years, cardiovascular research has benefitted from the application of MR statistical methods,10 which has allowed confirmation of causal relationships between different risk factors and certain cardiac diseases. In most cases, the association between these factors and diseases was well known beforehand; however, the aforementioned presence of possible biases (typical of observational studies) impeded inference of causal mechanisms with any certainty.
A good example that ideally illustrates the fundamental principles of these studies is found in a recently published article on the correlation between body mass index and certain heart diseases.11
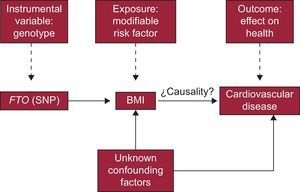
The researchers of this study questioned whether there was a causal relationship between excess body fat and the appearance of different cardiovascular diseases. Following an MR study strategy, the authors’ first step was to identify a genetic polymorphism (instrument) related to a risk factor (exposure) associated with a cardiac disease. In this case, they opted to use a single nucleotide polymorphism of the FTO gene (gene related to obesity and fat mass), which had been associated with the amount of body fat and body mass index in numerous previous studies.
The following step was to obtain the data necessary to carry out the statistical analysis. Specifically, information was obtained on the genotype and body mass index of >190000 participants, through different international studies done by the collaborating research groups. Afterward, the participants were divided into 2 groups according to the single nucleotide polymorphism variation of interest presented by each volunteer. As indicated in Figure 2, this step would be equivalent to randomization in an RCT.
The final step was to analyze the data obtained in the study, and the results of each group were compared according to the presence or absence of different cardiac diseases (coronary heart disease, heart failure, hemorrhagic stroke, hypertension, etc.), metabolic disorders (dyslipidemia, type 2 diabetes mellitus, and metabolic syndrome) or according to the values of several cardiometabolic factors (blood pressure, cholesterol, triglycerides, C-reactive protein, interleukin-6, etc).
The results showed the existence of a causal relationship between obesity and heart failure and also confirmed previous findings obtained from observational studies. The rationale behind this study is the following: if the effect of the chosen polymorphism (instrument) increases only the amount of body fat (risk factor), then it stands to reason that the cause of the observed increase in the incidence of heart failure is body mass index.
In short, and based on the general outline of the IV analysis shown earlier in a DAG (Figure 1), the particularities of this study are summarized in Figure 3.

Other studies with these characteristics have obtained equally relevant results. The article by Cohen et al12 deserves special mention. These authors showed the benefits of the persistent reduction of low-density lipoprotein concentrations on the number of myocardial infarctions. Another notable example is the study by Chen et al,13 which found a correlation in men between elevated alcohol consumption and hypertension. In contrast, the results of other research studies of this type contradict those obtained with conventional observational methods. A recent study14 that researched the association between the sPLA2 enzyme and cardiovascular disease was not able to find the putative relationship, contrary to reports from several traditional studies.
In concluding this section, it is worth mentioning that, obviously, this type of study also has certain limitations. First, there are the usual problems that can appear in any genetic association study, such as the existence of deviations in the expected allelic frequencies due to several causes (population stratification, existence of linkage disequilibrium phenomena, pleotropic activity of some genes, etc.) or problems with the sample size; given that the sample size is inversely proportional to the square of the correlation between the genetic instrument and the exposure and that it rarely exceeds 5% for genetic instruments, it is not always simple to obtain an appropriate number for these studies, which would be at least between 5000 and 100 000 patients in the most favorable scenario.15 Furthermore, there are some specific limitations to IV analyses, such as the difficulty of finding an appropriate instrument (simple or multiple polymorphism, or genetic risk scores) for the study of interest, the lack of compliance with the conditions that should be met by IV, or lack of statistical power.16
CONCLUSIONSMendelian randomization studies are an essential experimental approach for disentangling the causes of numerous cardiovascular diseases. Due to this methodology, important advances are currently being made in the study of correlations between different modifiable exposures and certain cardiac diseases. The possibility to establish true causal relationships in observational epidemiological studies where there is a suspicion of the existence of uncontrollable confounding factors has generated a wave of optimism within the scientific community. In observational epidemiological studies with suspected uncontrollable confounding factors, the possibility of establishing true causal relationships has generated a wave of optimism within the scientific community. This enthusiasm is corroborated by observing the exponential increase in the number of scientific studies based on this methodology published in recent years. Furthermore, the continuous development and advances of technologies associated with “omics”, together with the perfection of current statistical methods, will doubtlessly overcome current experimental limitations and confirm MR studies as fundamental tools for clinical research and therapeutic development. Consequently, these studies will become essential elements to support RCTs during the drafting of clinical practice guidelines and the implementation of public health policies and measures.
Lastly, important international coalitions have been created in recent years, which are in charge of the development and coordination of large biological resource centers. These organisms, often called biobanks, are every researcher's dream because they collect, store, and process all sorts of human biological samples and are a repository for abundant related data.17 These data include the results of research studies based on human biological samples that are directly applicable to MR analyses. Consequently, the exposure of interest does not need to be measured in the same population in which the outcome is observed. Thus, providing there are valid information sources about the effect of the gene in the exposure, this information could be directly linked to the genotype of the study population (and with the outcome measured) to make causal inferences by using the split sample design of MR studies. This is especially relevant because it avoids the need to once again measure the phenotype studied in the entire sample and only the genotype needs to be obtained, which represents an enormous cost savings.9
These circumstances, together with the inexorable advances of biomedical technologies, undoubtedly guarantee a promising future for MR studies.
CONFLICTS OF INTERESTNone declared.