ISSN: 0300-8932
Factor de impacto 2024
4,9
SEC 2024 - El Congreso de la Salud Cardiovascular

Bilbao,
24 - 26 de Octubre de 2024
Introducción
Dr. José María de la Torre Hernández
Presidente del Comité Científico del Congreso. Vicepresidente de la SEC
Comités ejecutivo, organizador y científico
Comité de evaluadores
Listado completo de comunicaciones
Índice de autores
6101. Ciencia traslacional y e-salud, el futuro de la investigación en cardiología
Fecha
: 24-10-2024 09:00:00
Tipo
: Póster moderado
Moderadores
: Rafael Carlos Vidal Pérez, Complexo Hospitalario Universitario de A Coruña, A Coruña
6101-2. Rendimiento de las expresiones regulares en el análisis de informes de alta presentes en la historia clínica electrónica: exprimiendo los datos secundarios
Alain García Olea1, Ane García Domingo-Aldama2, Marcos Merino Prado2, Koldo Gojenola Galletebeitia2, Aitziber Atutxa Salazar2, Mikel Maeztu Rada1, Iván García Díaz1, Adrián Costa1, Iván Cano1, Fernando Díaz1, Irene Hernández1, Uxue Millet1, Ainhoa Etxenike1 y José Miguel Ormaetxe Merodio1
1Hospital Universitario de Basurto, Bilbao (Vizcaya), España y 2Facultad de Ingeniería, Departamento de Lenguajes y Sistemas Informáticos. Universidad del País Vasco, Bilbao (Vizcaya), España.
1Hospital Universitario de Basurto, Bilbao (Vizcaya), España y 2Facultad de Ingeniería, Departamento de Lenguajes y Sistemas Informáticos. Universidad del País Vasco, Bilbao (Vizcaya), España.
Introducción y objetivos: Este estudio tiene como objetivo investigar cómo la aplicación de expresiones regulares (regex) identifica en los informes de alta de la historia clínica electrónica (HCE) variables no codificadas o mal codificadas en el sistema de informado. Se pretende demostrar cómo esta optimización del proceso de imputación puede mejorar la precisión de los algoritmos predictivos de recurrencia en una población con debut de fibrilación auricular (FA).
Métodos: Se realizó un análisis retrospectivo de los informes de alta en formato de texto libre (.txt) de pacientes con debut de FA entre 2015 y 2018. Se entrenó un modelo sobre el que se implementaron expresiones regulares para identificar y extraer información relevante de los informes, especialmente aquella relacionada con las variables codificadas, el debut de FA y su recurrencia. Se compararon los datos obtenidos mediante este método con los datos codificados y se utilizó la comprobación manual de la HCE como gold standard comparativo.
Resultados: Sobre un dataset de 2453 instancias, la aplicación de expresiones regulares sobre los informes de alta resultó en una reducción significativa (58,1%) del número de missing values en las variables analíticas codificadas (figura A). Además, gracias a la identificación de valores no codificados como los datos ecocardiográficos (figura B) se observó una mejora sustancial en la integridad y la completud de los datos. La herramienta identificó el debut de FA en el 88,23% de las instancias e identificó en el 61% de los informes datos relativos a la recurrencia o ausencia de recurrencia de FA.
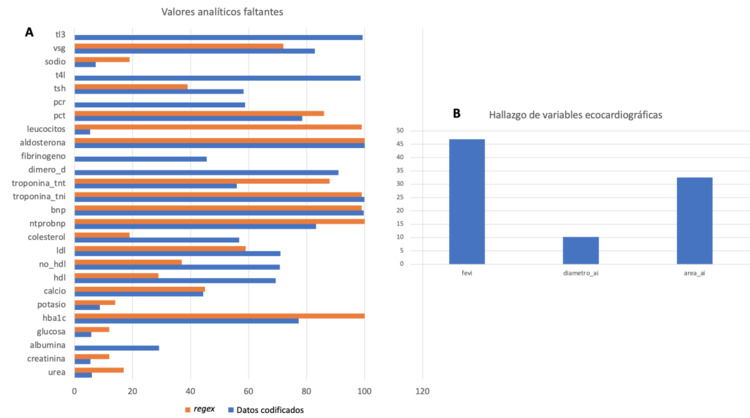
Porcentaje de valores faltantes en el análisis con regex frente a la codificación hospitalaria (A, %). Identificación de datos ecocardiográficos en informes de alta (B, %).
Conclusiones: Los resultados de este estudio respaldan la eficacia de utilizar expresiones regulares sobre los informes de alta de la historia clínica electrónica para disminuir los missing values en las variables analizadas para estudios a partir de datos secundarios. Además, el análisis de texto libre permite la optimización del proceso de imputación de datos al identificar variables no codificadas de forma sistemática.
Comunicaciones disponibles de "6101. Ciencia traslacional y e-salud, el futuro de la investigación en cardiología"
- 6101-1. Modera
- Rafael Carlos Vidal Pérez, Complexo Hospitalario Universitario de A Coruña, A Coruña
- 6101-2. Rendimiento de las expresiones regulares en el análisis de informes de alta presentes en la historia clínica electrónica: exprimiendo los datos secundarios
- Alain García Olea1, Ane García Domingo-Aldama2, Marcos Merino Prado2, Koldo Gojenola Galletebeitia2, Aitziber Atutxa Salazar2, Mikel Maeztu Rada1, Iván García Díaz1, Adrián Costa1, Iván Cano1, Fernando Díaz1, Irene Hernández1, Uxue Millet1, Ainhoa Etxenike1 y José Miguel Ormaetxe Merodio1
1Hospital Universitario de Basurto, Bilbao (Vizcaya), España y 2Facultad de Ingeniería, Departamento de Lenguajes y Sistemas Informáticos. Universidad del País Vasco, Bilbao (Vizcaya), España.
- 6101-3. Impacto en el coste sanitario de la implementación de la telemedicina en un programa multidisciplinar de insuficiencia cardiaca: subanálisis del ensayo clínico iCOR
- Herminio Morillas Climent1, Sergi Yun Viladomat1, Cristina Enjuanes Grau1, Alexandra Pons Riverola1, Raúl Ramos Polo1, Santiago Jiménez Marrero1, Pedro Moliner Borja1, Alberto Garay Melero1, Núria José Bazán1, Esther Calero Molina1, Encarnació Hidalgo Quirós1, Silvia Jovells Vaqué1, Miriam Corbella Santano1, José María Verdú Rotellar2 y Josep Comín Colet1
1Hospital Bellvitge, L'Hospitalet de Llobregat (Barcelona), España y 2Hospital del Mar, Barcelona, España.
- 6101-4. Concordancia entre intervenciones cardiológicas y propuestas de inteligencia artificial para pacientes que presentan dolor torácico, basadas en interconsultas desde el servicio de urgencias a cardiología
- Nuria Gil Mancebo1, Rebeca Mata Caballero1, Bárbara Izquierdo Coronel1, José Antonio Carnicero Carreno2, Paula Rodríguez Montes1, Silvia Humanes Ybañez1, Miguel de la Serna Real de Asúa1, María Martín Muñoz1, María Álvarez Bello1, Cristina Perela Álvarez1, Daniel Nieto Ibáñez1, Renée Olsen Rodríguez1, Alfonso Fraile Sanz1, María Jesús Espinosa Pascual1 y Joaquín J. Alonso Martín1
1Cardiología y 2Fundación para la Investigación Biomédica. Hospital Universitario de Getafe, Getafe (Madrid), España.
- 6101-5. Bloqueo de rama izquierda desde la perspectiva de big data: ¿podemos agregar algún valor pronóstico?
- Cristina de Cortina Camarero, María del Mar Sarrión Catalá, Laura Mora Yagüe, Silvia Jiménez Loeches, Cristina Beltrán Herrera, David Vaqueriza Cubillo, Verónica Suberviola Sánchez-Caballero, Alejandro Cortés Beringola, Pedro Martínez Losas, María Teresa Nogales Romo, Ana M. Sánchez Hernández y Roberto Muñoz Aguilera
Hospital Universitario Infanta Leonor, Madrid, España.
- 6101-6. Monitorización remota basada exclusivamente en alertas: ¿es posible implementarlo?
- Francisco Javier Méndez Zurita1, Jonathan Franklin Quispe Santos2, Enrique Rodríguez Font1, José M. Guerra Ramos1, Concepción Alonso Martín1, Bieito Campos García1, Zoraida L. Moreno Weidmann1, Maite Grande Osorio1, Isabel Ramírez de Diego1, Laura Sánchez Martín1, Daniel Majo Ramírez1, Elías Gilces Bravo1, Cristina Ybarra Falcón1, Licia Azocar Alcala1 y Xavier Viñolas Prat1
1Servicio de Cardiología. Hospital de la Santa Creu i Sant Pau, Barcelona, España y 2Medtronic Ibérica, Barcelona, España.
- 6101-7. Efecto de la mHealth en el pronóstico de los pacientes con insuficiencia cardiaca en el periodo transicional post alta en función de la fracción de eyección del ventrículo izquierdo: subanálisis del ensayo clínico multicéntrico, aleatorizado y controlado HERMeS
- Alexandra Pons Riverola1, Sergi Yun Viladomat1, Pedro Moliner Borja1, Marta Cobo Marcos2, Pau Llácer Iborra3, José Manuel García Pinilla4, Álvaro González Franco5, José Luis Morales Rull6, Elena García Romero1, Julio Núñez Villota7, Coral Fernández Solana1, Sílvia Jovells Vaqué1, Míriam Corbella Santano1, Cristina Enjuanes Grau1 y Josep Comín Colet1
1Hospital Universitari de Bellvitge, L'Hospitalet de Llobregat (Barcelona), España, 2Hospital Universitario Puerta de Hierro, Majadahonda (Madrid), España, 3Hospital Universitario Ramón y Cajal, Madrid, España, 4Hospital Clínico Universitario Virgen de la Victoria, Málaga, España, 5Hospital Universitario Central de Asturias, Oviedo (Asturias), España, 6Hospital Universitari Arnau de Vilanova, Lleida, España y 7Hospital Clínico Universitario de Valencia, Valencia, España.
- 6101-8. Perfil de la insuficiencia cardiaca con fracción de eyección preservada o levemente reducida mediante análisis de conglomerados
- Nicolás Rosillo Ramírez1, Jorge Vélez García1, Guillermo Moreno Muñoz1, Pablo Pérez Ruiz2, Miguel Hernández Gómez1, Rafael Salguero Bodes3, Fernando Arribas Ynsaurriaga3, José Luis Bernal Sobrino1, Germán Seara Aguilar1, Héctor Bueno Zamora1 y Lourdes Vicent Alaminos1
1Grupo de Investigación Cardiovascular Multidisciplinar Traslacional. Instituto de Investigación Hospital 12 de Octubre (i+12), Madrid, España, 2Servicio de Medicina Preventiva. Hospital Clínico San Carlos, Madrid, España y 3Servicio de Cardiología. Hospital Universitario 12 de Octubre, Madrid, España.
- 6101-9. SCACEST en pacientes muy jóvenes: cronometrando la respuesta para un futuro libre de eventos cardiovasculares mayores
- Pablo Juan-Salvadores1, Luis Mariano de la Torre Fonseca2, Beatriz Calderón Cruz3, César Veiga García1, Samuel Pintos Rodríguez1, Laura Busto Castiñeira1, Saleta Fernández Barbeira4, Andrés Íñiguez Romo5, Víctor Alfonso Jiménez Díaz4 y. Grupo Regaliam6
1Unidad de Investigación Cardiovascular. Servicio de Cardiología. Hospital Álvaro Cunqueiro, Vigo (Pontevedra), España, 2Unidad de Cuidados Intensivos. Hospital Universitario Clínico-Quirúrgico Comandante Manuel Fajardo, La Habana (Cuba), 3Unidad de Metodología y Estadística (UME). Hospital Álvaro Cunqueiro, Vigo (Pontevedra), España, 4Unidad de Hemodinámica y Cardiología Intervencionista. Servicio de Cardiología. Hospital Álvaro Cunqueiro, Vigo (Pontevedra), España, 5Servicio de Cardiología. Hospital Álvaro Cunqueiro, Vigo (Pontevedra), España y 6Hospital Álvaro Cunqueiro, Vigo (Pontevedra), España.
- 6101-10. Efecto de la mHealth en los pacientes con insuficiencia cardiaca en fase vulnerable según el nivel de péptidos natriuréticos: subanálisis del ensayo clínico multicéntrico, aleatorizado y controlado HERMeS
- Alexandra Pons Riverola1, Sergi Yun Viladomat1, Pedro Moliner Borja1, Marta Cobo Marcos2, José Manuel García Pinilla3, Elena García Romero1, Julio Núñez Villota4, Francesc Formiga Pérez1, Javier de Juan Bagudá5, Isabel Zegrí Reiriz6, Mercedes Faraudo García7, Sílvia Jovells Vaqué1, Míriam Corbella Santano1, Cristina Enjuanes Grau1 y Josep Comín Colet1
1Hospital Universitari de Bellvitge, L'Hospitalet de Llobregat (Barcelona), España, 2Hospital Universitario Puerta de Hierro, Majadahonda (Madrid), España, 3Hospital Clínico Universitario Virgen de la Victoria, Málaga, España, 4Hospital Clínico Universitario de Valencia, Valencia, España, 5Hospital Universitario 12 de Octubre, Madrid, España, 6Hospital de la Santa Creu i Sant Pau, Barcelona, España y 7Hospital Sant Joan Despí-Moisès Broggi, Sant Joan Despí (Barcelona), España.
- 6101-11. El secretoma liberado por células derivadas de cardioesferas precondicionadas con IFN-γ como alternativa terapéutica en el tratamiento del infarto de miocardio
- Claudia Baez Díaz1, María Ángeles de Pedro2, Verónica Álvarez3, Ana María Marchena4, Verónica Crisóstomo Ayala1, Francisco Miquel Sánchez-Margallo1, Esther López Nieto1 y María Pulido Fresneda3
1Fundación Centro de Cirugía de Mínima Invasión Jesús Usón; CIBER de Enfermedades Cardiovasculares (CIBERCV); Red RICORS-TERAV, ISCIII, Cáceres, España, 2Fundación Centro de Cirugía de Mínima Invasión Jesús Usón; Red RICORS-TERAV, ISCIII, Cáceres, España, 3Fundación Centro de Cirugía de Mínima Invasión Jesús Usón, Cáceres, España y 4Fundación Centro de Cirugía de Mínima Invasión Jesús Usón; Red RICORS-TERAV, ISCIII, Cáceres, España.
- 6101-12. Diferente perfil proteómico en sangre de pacientes con insuficiencia cardiaca en función de la presencia de déficit de hierro
- Josep Francesch Manzano1, Marta Tajes Orduña2, Raúl Ramos-Polo3, María del Mar Ras-Jiménez3, Sílvia Jovells-Vaqué4, Míriam Corbella Santano4, Núria José-Bazán3, Herminio Morillas Climent3, Santiago Jiménez Marrero3, Sergi Yun Viladomat5, Pedro Moliner Borja5, Carles Díez López6, José González Costello7, Cristina Enjuanes Grau5 y Josep Comín Colet5
1Centro de Investigación Biomédica en Red Enfermedades Cardiovasculares (CIBERCV), España. Grupo BioHeart-Enfermedades Cardiovasculares. IDIBELL-Instituto de Investigación Biomédica de Bellvitge, L'Hospitalet de Llobregat (Barcelona), España, 2Centro de Investigación Biomédica en Red Enfermedades Cardiovasculares (CIBERCV), España. Grupo BioHeart-Enfermedades Cardiovasculares. IDIBELL- Instituto de Investigación Biomédica de Bellvitge, L'Hospitalet de Llobregat (Barcelona), España, 3Grupo BioHeart-enfermedades cardiovasculares (IDIBELL), L'Hospitalet del Llobregat (Barcelona)-España. Programa de Insuficiencia Cardiaca Comunitaria, Servicio de Cardiología. Hospital Bellvitge, L'Hospitalet de Llobregat (Barcelona), España, 4Grupo BioHeart-enfermedades cardiovasculares. IDIBELL- Instituto de Investigación Biomédica de Bellvitge, L'Hospitalet de Llobregat (Barcelona), España, 5Centro de Investigación Biomédica en Red Enfermedades Cardiovasculares (CIBERCV), Spain. Programa de Insuficiencia Cardiaca Comunitaria, Servicio de Cardiología. Hospital Bellvitge, L'Hospitalet de Llobregat (Barcelona), España, 6Grupo BioHeart-enfermedades Cardiovasculares (IDIBELL), L'Hospitalet del Llobregat (Barcelona)-España. Insuficiencia Cardiaca Avanzada y Enfermedades Cardiacas Hereditarias. Hospital Bellvitge, L'Hospitalet de Llobregat (Barcelona), España y 7Centro de Investigación Biomédica en Red Enfermedades Cardiovasculares (CIBERCV), España. Insuficiencia Cardiaca Avanzada y Enfermedades Cardiacas Hereditarias. Hospital Bellvitge, L'Hospitalet de Llobregat (Barcelona), España.
- 6101-13. Análisis de coste-utilidad de los inhibidores de PCSK9 y calidad de vida: un estudio multicéntrico no aleatorizado de dos años
- José Seijas Amigo1, Francisco Reyes Santías2, María Jesús Mauriz Montero3, Pedro Suárez Artime4, Mónica Gayoso Rey5, Ana Estany Gestal6, Marta Ribeiro Ferreiro1, Diego Rodríguez Penas1, Begoña Cardeso Paredes1, Antonia Casas Martínez7, Lara González Freire8, Ana Rodríguez Vázquez9, Moisés Rodríguez Mañero10, Alberto Cordero Fort11 y José Ramón González Juanatey10
1Cardiología. Fundación Idichus, Santiago de Compostela (A Coruña), España, 2Gerencia. Fundación Idichus, Santiago de Compostela (A Coruña), España, 3Farmacia. Complexo Hospitalario Universitario A Coruña, A Coruña, España, 4Farmacia. Complexo Hospitalario Universitario de Santiago de Compostela, Santiago de Compostela (A Coruña), España, 5Farmacia. Hospital Álvaro Cunqueiro, Vigo (Pontevedra), España, 6Epidemiología. Fundación Idichus, Santiago de Compostela (A Coruña), España, 7Farmacia. Hospital Arquitecto Marcide, Ferrol (A Coruña), España, 8Farmacia. Complejo Hospitalario de Pontevedra, Pontevedra, España, 9Farmacia. Complexo Hospitalario, Ourense, España, 10Cardiología. Complexo Hospitalario Universitario de Santiago de Compostela, Santiago de Compostela (A Coruña), España y 11Cardiología. Hospital IMED Elche, Elche (Alicante), España.
- 6101-14. Futilidad, fragilidad y comorbilidad en el paciente TAVI (presentación de la FFC-TAVI Score)
- Isaac Vidal Valdivia, Lucy Daniela Campos Vega, José Ramírez Batista, Jonathan Calavia Arriazu, Nur Rahma Almaraz, Teresa Gonzalo Moreno, Alejandro Gutiérrez Fernández, Pablo Aguiar Souto, M. Pilar Portero Pérez, Guillermo Pinillos Francia, Beatriz Moreno Djadou, Javier Ibero Valencia, David de las Cuevas León, Gabriel Hurtado Rodríguez y Lizandro Rodríguez Hernández
Servicio de Cardiología. Complejo Hospitalario San Millán-San Pedro, Logroño (La Rioja), España.
- 6101-15. Recomendaciones de un grupo de expertos para mejorar la atención a los pacientes tras un infarto agudo de miocardio
- Sergio Raposeiras Roubin1, Guillermo Aldama López2, Rut Andrea Riba3, Miguel José Corbi Pascual4, Alberto Cordero Fort5, María Rosa Fernández Olmo6, Xavier García Moll7, Antonio García Quintana8, Arantxa Matali Gilarranz9, Miriam Sandín Rollán10, Xoana Taboada Penoucos11, Ana Viana Tejedor12 y José M. de la Torre Hernández13
1Cardiología. Hospital Álvaro Cunqueiro, Vigo (Pontevedra), España, 2Cardiología. Complexo Hospitalario Universitario A Coruña, A Coruña, España, 3Hospital Clínic, Barcelona, España, 4Complejo Hospitalario Universitario de Albacete, Albacete, España, 5Hospital IMED Elche, Elche (Alicante), España, 6Complejo Hospitalario de Jaén, Jaén, España, 7Hospital de la Santa Creu i Sant Pau, Barcelona, España, 8Hospital Universitario de Gran Canaria Dr. Negrín, Las Palmas de Gran Canaria (Las Palmas), España, 9Boehringer Ingelheim España, Barcelona, España, 10Hospital General Universitario de Alicante, Alicante, España, 11Eli Lilly and Company España, Madrid, España, 12Hospital Clínico San Carlos, Madrid, España y 13Hospital Universitario Marqués de Valdecilla, Santander (Cantabria), España.
- 6101-16. Evaluando la capacidad de la inteligencia artificial en la adecuación de informes clínicos para la alfabetización en salud del paciente cardiológico
- Sarai Suárez Sampedro1, María Calvo Barceló2 y Marco Tomasino2
1Hospital Universitari Vall d'Hebron, Barcelona, España y 2Servicio de Cardiología. Hospital Universitari Vall d'Hebron, Barcelona, España.
Más comunicaciones de los autores
-
Atutxa Salazar, Aitziber
- 6101-2 - Rendimiento de las expresiones regulares en el análisis de informes de alta presentes en la historia clínica electrónica: exprimiendo los datos secundarios
- 6075-469 - Rendimiento de sistemas de chat alimentados con artículos de investigación en un entorno clínico específico: la enfermedad valvular cardiaca
-
Cano González, Iván
- 6075-469 - Rendimiento de sistemas de chat alimentados con artículos de investigación en un entorno clínico específico: la enfermedad valvular cardiaca
- 6120-6 - Unidad multidisciplinar en la enfermedad de Steinert: una visión desde cardiología
- 6101-2 - Rendimiento de las expresiones regulares en el análisis de informes de alta presentes en la historia clínica electrónica: exprimiendo los datos secundarios
- 6081-494 - Fibrilación auricular subclínica y su relación con eventos adversos en el seguimiento por monitorización remota de los pacientes portadores de marcapasos doble cámara
- 6085-510 - Experiencia de nuestro centro en el campo de la ablación de venas pulmonares con electroporación durante el último año. Análisis de tiempos de procedimiento, tasa de complicaciones y eficacia frente a los métodos actuales
- 5004-5 - Experiencia inicial de nuestro centro en la ablación del istmo mitral mediante electroporación para el abordaje de la fibrilación auricular
- 6052-340 - Valor de la ergoespirometría fusionada con ecocardiografía de estrés en la valoración de la disnea de nueva aparición tras tratamiento oncológico con potencial cardiotóxico
-
Costa Santos, Adrián
- 6101-2 - Rendimiento de las expresiones regulares en el análisis de informes de alta presentes en la historia clínica electrónica: exprimiendo los datos secundarios
- 6085-510 - Experiencia de nuestro centro en el campo de la ablación de venas pulmonares con electroporación durante el último año. Análisis de tiempos de procedimiento, tasa de complicaciones y eficacia frente a los métodos actuales
- 6075-469 - Rendimiento de sistemas de chat alimentados con artículos de investigación en un entorno clínico específico: la enfermedad valvular cardiaca
- 6120-6 - Unidad multidisciplinar en la enfermedad de Steinert: una visión desde cardiología
- 6052-340 - Valor de la ergoespirometría fusionada con ecocardiografía de estrés en la valoración de la disnea de nueva aparición tras tratamiento oncológico con potencial cardiotóxico
- 5004-5 - Experiencia inicial de nuestro centro en la ablación del istmo mitral mediante electroporación para el abordaje de la fibrilación auricular
- Díaz, Fernando
- Etxenike, Ainhoa
-
García Díaz, Iván
- 6101-2 - Rendimiento de las expresiones regulares en el análisis de informes de alta presentes en la historia clínica electrónica: exprimiendo los datos secundarios
- 4028-3 - Disfunción cardiaca por anti-Her2 en la era de la cardiotoxicidad permisiva
- 5004-5 - Experiencia inicial de nuestro centro en la ablación del istmo mitral mediante electroporación para el abordaje de la fibrilación auricular
- 6081-494 - Fibrilación auricular subclínica y su relación con eventos adversos en el seguimiento por monitorización remota de los pacientes portadores de marcapasos doble cámara
- 6120-6 - Unidad multidisciplinar en la enfermedad de Steinert: una visión desde cardiología
- 6075-469 - Rendimiento de sistemas de chat alimentados con artículos de investigación en un entorno clínico específico: la enfermedad valvular cardiaca
- 6085-510 - Experiencia de nuestro centro en el campo de la ablación de venas pulmonares con electroporación durante el último año. Análisis de tiempos de procedimiento, tasa de complicaciones y eficacia frente a los métodos actuales
-
García Domingo-Aldama, Ane
- 6101-2 - Rendimiento de las expresiones regulares en el análisis de informes de alta presentes en la historia clínica electrónica: exprimiendo los datos secundarios
- 6075-469 - Rendimiento de sistemas de chat alimentados con artículos de investigación en un entorno clínico específico: la enfermedad valvular cardiaca
-
García Olea, Alain
- 6101-2 - Rendimiento de las expresiones regulares en el análisis de informes de alta presentes en la historia clínica electrónica: exprimiendo los datos secundarios
- 6075-469 - Rendimiento de sistemas de chat alimentados con artículos de investigación en un entorno clínico específico: la enfermedad valvular cardiaca
-
Gojenola Galletebeitia, Koldo
- 6075-469 - Rendimiento de sistemas de chat alimentados con artículos de investigación en un entorno clínico específico: la enfermedad valvular cardiaca
- 6101-2 - Rendimiento de las expresiones regulares en el análisis de informes de alta presentes en la historia clínica electrónica: exprimiendo los datos secundarios
-
Hernández Pérez, Irene
- 6052-340 - Valor de la ergoespirometría fusionada con ecocardiografía de estrés en la valoración de la disnea de nueva aparición tras tratamiento oncológico con potencial cardiotóxico
- 6120-6 - Unidad multidisciplinar en la enfermedad de Steinert: una visión desde cardiología
- 6075-469 - Rendimiento de sistemas de chat alimentados con artículos de investigación en un entorno clínico específico: la enfermedad valvular cardiaca
- 6101-2 - Rendimiento de las expresiones regulares en el análisis de informes de alta presentes en la historia clínica electrónica: exprimiendo los datos secundarios
- 4028-3 - Disfunción cardiaca por anti-Her2 en la era de la cardiotoxicidad permisiva
-
Maeztu Rada, Mikel
- 4028-3 - Disfunción cardiaca por anti-Her2 en la era de la cardiotoxicidad permisiva
- 6075-469 - Rendimiento de sistemas de chat alimentados con artículos de investigación en un entorno clínico específico: la enfermedad valvular cardiaca
- 6052-340 - Valor de la ergoespirometría fusionada con ecocardiografía de estrés en la valoración de la disnea de nueva aparición tras tratamiento oncológico con potencial cardiotóxico
- 6101-2 - Rendimiento de las expresiones regulares en el análisis de informes de alta presentes en la historia clínica electrónica: exprimiendo los datos secundarios
-
Merino Prado, Marcos
- 6101-2 - Rendimiento de las expresiones regulares en el análisis de informes de alta presentes en la historia clínica electrónica: exprimiendo los datos secundarios
- 6075-469 - Rendimiento de sistemas de chat alimentados con artículos de investigación en un entorno clínico específico: la enfermedad valvular cardiaca
- Millet, Uxue
-
Ormaetxe Merodio, José Miguel
- 6075-469 - Rendimiento de sistemas de chat alimentados con artículos de investigación en un entorno clínico específico: la enfermedad valvular cardiaca
- 6101-2 - Rendimiento de las expresiones regulares en el análisis de informes de alta presentes en la historia clínica electrónica: exprimiendo los datos secundarios
- 6120-3 - Los parámetros electrocardiográficos nativos que incluyen la heterogeneidad de la repolarización como predictores útiles del desarrollo de la miocardiopatía inducida por la estimulación apical del ventrículo derecho
- 5004-5 - Experiencia inicial de nuestro centro en la ablación del istmo mitral mediante electroporación para el abordaje de la fibrilación auricular
- 6081-494 - Fibrilación auricular subclínica y su relación con eventos adversos en el seguimiento por monitorización remota de los pacientes portadores de marcapasos doble cámara
- 6085-510 - Experiencia de nuestro centro en el campo de la ablación de venas pulmonares con electroporación durante el último año. Análisis de tiempos de procedimiento, tasa de complicaciones y eficacia frente a los métodos actuales