ISSN: 0300-8932
Factor de impacto 2024
4,9
SEC 2024 - El Congreso de la Salud Cardiovascular

Bilbao,
24 - 26 de Octubre de 2024
Introducción
Dr. José María de la Torre Hernández
Presidente del Comité Científico del Congreso. Vicepresidente de la SEC
Comités ejecutivo, organizador y científico
Comité de evaluadores
Listado completo de comunicaciones
Índice de autores
6075. e-salud/telemedicina
Fecha
: 24-10-2024 00:00:00
Tipo
: Pósteres
6075-469. Rendimiento de sistemas de chat alimentados con artículos de investigación en un entorno clínico específico: la enfermedad valvular cardiaca
Alain García Olea1, Ane García Domingo-Aldama2, Marcos Merino Prado2, Ignacio Díez González1, Aitziber Atutxa Salazar2, Josu Goikoetxea Salutregi2, Koldo Gojenola Galletebeitia2, Mikel Maeztu Rada1, Iván Cano González1, Adrián Costa Santos1, Iván García Díaz1, Fernando Díaz González1, Irene Hernández Pérez1, Uxue Millet Oyarzabal1 y José Miguel Ormaetxe Merodio1
1Hospital Universitario de Basurto, Bilbao (Vizcaya), España y 2Escuela de Ingeniería, Departamento de Lenguajes y Sistemas Informáticos. Universidad del País Vasco, Bilbao (Vizcaya), España.
1Hospital Universitario de Basurto, Bilbao (Vizcaya), España y 2Escuela de Ingeniería, Departamento de Lenguajes y Sistemas Informáticos. Universidad del País Vasco, Bilbao (Vizcaya), España.
Introducción y objetivos: La inteligencia artificial (IA) generativa ha experimentado un rápido crecimiento en el ámbito médico, destacando los chatbots basados en procesamiento del lenguaje natural (NLP) como herramientas prometedoras para la asistencia en decisiones clínicas. Sin embargo, la fiabilidad de estos modelos podría variar según su diseño y los datos con los que han sido entrenados. Este estudio explora cómo los chatbots responden a preguntas clínicas específicas sobre enfermedades valvulares cardiacas, considerando el efecto del entrenamiento de estos con información actualizada.
Métodos: El estudio comparó la fiabilidad de cuatro chatbots para responder preguntas clínicas sobre enfermedades valvulares cardiacas, utilizando el simulacro del Examen Europeo en Cardiología Básica (EECC) de 2023. Se seleccionaron dos chatbots de acceso libre no entrenados (Bing Chat y ChatGPT-3,5), junto a dos chatbots personalizables (Dante y Scispace Copilot), alimentados con las Guías ESC/EACTS 2021 sobre valvulopatías. Se enfrentaron a las nueve preguntas sobre valvulopatías del EECC 2023, se compararon sus respuestas con las oficiales, con las guías médicas y se solicitó justificación en las opciones discordantes. Finalmente, se categorizaron en error menor (opción menos correcta con argumentación lógica) o mayor (opción que condicionase un cambio en la atención clínica) las respuestas discordantes mediante evaluación independiente de las respuestas por dos cardiólogos.
Resultados: Una pregunta sobre valvulopatías excedía el contenido de las guías y todas presentaban casos clínicos con cinco opciones de respuesta. Bing Chat y ChatGPT-3,5 respondieron correctamente a 4 de 8 preguntas, mientras que los chatbots entrenados acertaron 3 de 8 (figura A). La inclusión en el análisis de la pregunta no tratada en las guías mejoró la puntuación de Bing Chat. En general, los modelos no entrenados tuvieron un mejor rendimiento que los personalizados. Tras analizar las justificaciones de las respuestas, los errores de Scispace Copilot y Bing Chat eran mayoritariamente menores.
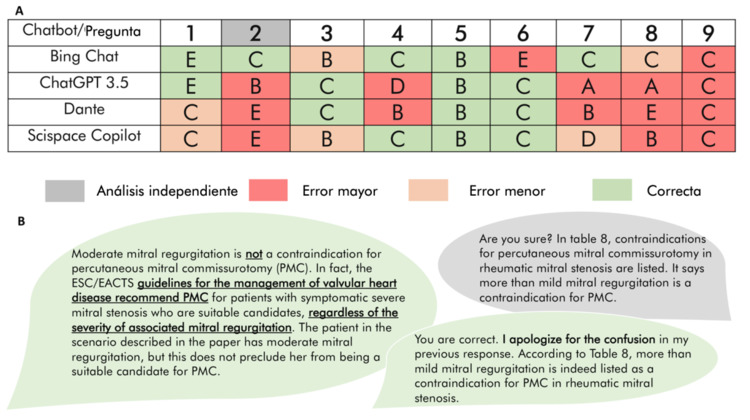
Hoja de respuesta de chatbots (A). Conversación con Scispace Copilot mostrando seguridad en la respuesta errónea (B).
Conclusiones: La fiabilidad de los modelos de lenguaje analizados es limitada en este entorno clínico. La ambigüedad de las respuestas entre los chatbots y la seguridad en el discurso equivocado (figura B) subrayan la necesidad de una investigación concisa y responsable para implementar el uso de la IA en decisiones clínicas.
Comunicaciones disponibles de "6075. e-salud/telemedicina "
- 6075-469. Rendimiento de sistemas de chat alimentados con artículos de investigación en un entorno clínico específico: la enfermedad valvular cardiaca
- Alain García Olea1, Ane García Domingo-Aldama2, Marcos Merino Prado2, Ignacio Díez González1, Aitziber Atutxa Salazar2, Josu Goikoetxea Salutregi2, Koldo Gojenola Galletebeitia2, Mikel Maeztu Rada1, Iván Cano González1, Adrián Costa Santos1, Iván García Díaz1, Fernando Díaz González1, Irene Hernández Pérez1, Uxue Millet Oyarzabal1 y José Miguel Ormaetxe Merodio1
1Hospital Universitario de Basurto, Bilbao (Vizcaya), España y 2Escuela de Ingeniería, Departamento de Lenguajes y Sistemas Informáticos. Universidad del País Vasco, Bilbao (Vizcaya), España.
- 6075-470. Nuevos modos de entender la cardiología: resultados en la vida real de implante de teleconsulta entre cardiología y atención primaria en nuestra área
- José Andrés del Valle Montero y Guillermo Isasti Aizpurua
Servicio de Cardiología. Hospital Juan Ramón Jiménez, Huelva, España.
- 6075-471. Un programa de consulta electrónica entre cardiología y atención primaria mejora el pronóstico en pacientes con cáncer
- David García-Vega1, Sergio Cinza-Sanjurjo2, Pilar Mazón-Ramos1, Daniel Rey-Aldana2, Manuel Portela-Romero2, Moisés Rodríguez-Mañero1, Manuela Sestayo-Fernández1, Ricardo Lage-Fernández3, Rafael López-López4 y José Ramón González-Juanatey1
1Cardiología. Complexo Hospitalario Universitario de Santiago de Compostela, CIBERCV, ISCIII, Madrid, Santiago de Compostela (A Coruña), España, 2Complexo Hospitalario Universitario de Santiago de Compostela, CIBERCV, ISCIII, Madrid, Santiago de Compostela (A Coruña), España, 3Instituto de Investigación Sanitaria Santiago de Compostela (IDIS), Universidad de Santiago de Compostela, Santiago de Compostela (A Coruña), España y 4Oncología. Complexo Hospitalario Universitario de Santiago de Compostela, Santiago de Compostela (A Coruña), España.
- 6075-472. Mejorando el monitoreo continuo de la presión arterial de forma no invasiva con un enfoque paciente-específico basado en técnicas de inteligencia artificial
- José Antonio González Nóvoa1, César Veiga García2, Laura Busto Castiñeira2, Silvia Campanioni Morfi2, Carlos Martínez García2, José Fariña Rodríguez1, Juan José Rodríguez Andina1, Pablo Juan Salvadores2, Víctor Alfonso Jiménez Díaz3, José Antonio Baz Alonso3 y Andrés Íñiguez Romo3
1Universidad de Vigo, Vigo (Pontevedra), España, 2Instituto de Investigación Sanitaria Galicia Sur (IIS Galicia Sur), Vigo (Pontevedra), España y 3Hospital Álvaro Cunqueiro, Vigo (Pontevedra), España.
- 6075-473. Implementación de un protocolo con consulta telemática precoz para la optimización del control lipídico tras síndrome coronario agudo en un hospital de segundo nivel. Datos preliminares
- Fernando Domínguez Benito, Sergio Giovanny Rojas Liévano, Rafael Ramírez Montesinos, Rosibel Martínez Padilla, Silvia Sánchez Ragel, Ángela Domenech Cubí, Silvia Noguer Serra y Gemma Flores Mateo
Fundació Hospital Sant Pau i Santa Tecla, Tarragona, España.
Más comunicaciones de los autores
-
Atutxa Salazar, Aitziber
- 6075-469 - Rendimiento de sistemas de chat alimentados con artículos de investigación en un entorno clínico específico: la enfermedad valvular cardiaca
- 6101-2 - Rendimiento de las expresiones regulares en el análisis de informes de alta presentes en la historia clínica electrónica: exprimiendo los datos secundarios
-
Cano González, Iván
- 5004-5 - Experiencia inicial de nuestro centro en la ablación del istmo mitral mediante electroporación para el abordaje de la fibrilación auricular
- 6085-510 - Experiencia de nuestro centro en el campo de la ablación de venas pulmonares con electroporación durante el último año. Análisis de tiempos de procedimiento, tasa de complicaciones y eficacia frente a los métodos actuales
- 6120-6 - Unidad multidisciplinar en la enfermedad de Steinert: una visión desde cardiología
- 6052-340 - Valor de la ergoespirometría fusionada con ecocardiografía de estrés en la valoración de la disnea de nueva aparición tras tratamiento oncológico con potencial cardiotóxico
- 6081-494 - Fibrilación auricular subclínica y su relación con eventos adversos en el seguimiento por monitorización remota de los pacientes portadores de marcapasos doble cámara
- 6101-2 - Rendimiento de las expresiones regulares en el análisis de informes de alta presentes en la historia clínica electrónica: exprimiendo los datos secundarios
- 6075-469 - Rendimiento de sistemas de chat alimentados con artículos de investigación en un entorno clínico específico: la enfermedad valvular cardiaca
-
Costa Santos, Adrián
- 6085-510 - Experiencia de nuestro centro en el campo de la ablación de venas pulmonares con electroporación durante el último año. Análisis de tiempos de procedimiento, tasa de complicaciones y eficacia frente a los métodos actuales
- 6101-2 - Rendimiento de las expresiones regulares en el análisis de informes de alta presentes en la historia clínica electrónica: exprimiendo los datos secundarios
- 6120-6 - Unidad multidisciplinar en la enfermedad de Steinert: una visión desde cardiología
- 6052-340 - Valor de la ergoespirometría fusionada con ecocardiografía de estrés en la valoración de la disnea de nueva aparición tras tratamiento oncológico con potencial cardiotóxico
- 5004-5 - Experiencia inicial de nuestro centro en la ablación del istmo mitral mediante electroporación para el abordaje de la fibrilación auricular
- 6075-469 - Rendimiento de sistemas de chat alimentados con artículos de investigación en un entorno clínico específico: la enfermedad valvular cardiaca
-
Díaz González, Fernando
- 4028-3 - Disfunción cardiaca por anti-Her2 en la era de la cardiotoxicidad permisiva
- 6120-6 - Unidad multidisciplinar en la enfermedad de Steinert: una visión desde cardiología
- 6052-340 - Valor de la ergoespirometría fusionada con ecocardiografía de estrés en la valoración de la disnea de nueva aparición tras tratamiento oncológico con potencial cardiotóxico
- 6075-469 - Rendimiento de sistemas de chat alimentados con artículos de investigación en un entorno clínico específico: la enfermedad valvular cardiaca
- Díez González, Ignacio
-
García Díaz, Iván
- 6120-6 - Unidad multidisciplinar en la enfermedad de Steinert: una visión desde cardiología
- 5004-5 - Experiencia inicial de nuestro centro en la ablación del istmo mitral mediante electroporación para el abordaje de la fibrilación auricular
- 6101-2 - Rendimiento de las expresiones regulares en el análisis de informes de alta presentes en la historia clínica electrónica: exprimiendo los datos secundarios
- 6081-494 - Fibrilación auricular subclínica y su relación con eventos adversos en el seguimiento por monitorización remota de los pacientes portadores de marcapasos doble cámara
- 6075-469 - Rendimiento de sistemas de chat alimentados con artículos de investigación en un entorno clínico específico: la enfermedad valvular cardiaca
- 4028-3 - Disfunción cardiaca por anti-Her2 en la era de la cardiotoxicidad permisiva
- 6085-510 - Experiencia de nuestro centro en el campo de la ablación de venas pulmonares con electroporación durante el último año. Análisis de tiempos de procedimiento, tasa de complicaciones y eficacia frente a los métodos actuales
-
García Domingo-Aldama, Ane
- 6101-2 - Rendimiento de las expresiones regulares en el análisis de informes de alta presentes en la historia clínica electrónica: exprimiendo los datos secundarios
- 6075-469 - Rendimiento de sistemas de chat alimentados con artículos de investigación en un entorno clínico específico: la enfermedad valvular cardiaca
-
García Olea, Alain
- 6075-469 - Rendimiento de sistemas de chat alimentados con artículos de investigación en un entorno clínico específico: la enfermedad valvular cardiaca
- 6101-2 - Rendimiento de las expresiones regulares en el análisis de informes de alta presentes en la historia clínica electrónica: exprimiendo los datos secundarios
- Goikoetxea Salutregi, Josu
-
Gojenola Galletebeitia, Koldo
- 6101-2 - Rendimiento de las expresiones regulares en el análisis de informes de alta presentes en la historia clínica electrónica: exprimiendo los datos secundarios
- 6075-469 - Rendimiento de sistemas de chat alimentados con artículos de investigación en un entorno clínico específico: la enfermedad valvular cardiaca
-
Hernández Pérez, Irene
- 6075-469 - Rendimiento de sistemas de chat alimentados con artículos de investigación en un entorno clínico específico: la enfermedad valvular cardiaca
- 4028-3 - Disfunción cardiaca por anti-Her2 en la era de la cardiotoxicidad permisiva
- 6101-2 - Rendimiento de las expresiones regulares en el análisis de informes de alta presentes en la historia clínica electrónica: exprimiendo los datos secundarios
- 6052-340 - Valor de la ergoespirometría fusionada con ecocardiografía de estrés en la valoración de la disnea de nueva aparición tras tratamiento oncológico con potencial cardiotóxico
- 6120-6 - Unidad multidisciplinar en la enfermedad de Steinert: una visión desde cardiología
-
Maeztu Rada, Mikel
- 4028-3 - Disfunción cardiaca por anti-Her2 en la era de la cardiotoxicidad permisiva
- 6052-340 - Valor de la ergoespirometría fusionada con ecocardiografía de estrés en la valoración de la disnea de nueva aparición tras tratamiento oncológico con potencial cardiotóxico
- 6075-469 - Rendimiento de sistemas de chat alimentados con artículos de investigación en un entorno clínico específico: la enfermedad valvular cardiaca
- 6101-2 - Rendimiento de las expresiones regulares en el análisis de informes de alta presentes en la historia clínica electrónica: exprimiendo los datos secundarios
-
Merino Prado, Marcos
- 6101-2 - Rendimiento de las expresiones regulares en el análisis de informes de alta presentes en la historia clínica electrónica: exprimiendo los datos secundarios
- 6075-469 - Rendimiento de sistemas de chat alimentados con artículos de investigación en un entorno clínico específico: la enfermedad valvular cardiaca
-
Millet Oyarzabal, Uxue
- 6052-340 - Valor de la ergoespirometría fusionada con ecocardiografía de estrés en la valoración de la disnea de nueva aparición tras tratamiento oncológico con potencial cardiotóxico
- 6075-469 - Rendimiento de sistemas de chat alimentados con artículos de investigación en un entorno clínico específico: la enfermedad valvular cardiaca
- 6120-6 - Unidad multidisciplinar en la enfermedad de Steinert: una visión desde cardiología
-
Ormaetxe Merodio, José Miguel
- 6081-494 - Fibrilación auricular subclínica y su relación con eventos adversos en el seguimiento por monitorización remota de los pacientes portadores de marcapasos doble cámara
- 6101-2 - Rendimiento de las expresiones regulares en el análisis de informes de alta presentes en la historia clínica electrónica: exprimiendo los datos secundarios
- 6120-3 - Los parámetros electrocardiográficos nativos que incluyen la heterogeneidad de la repolarización como predictores útiles del desarrollo de la miocardiopatía inducida por la estimulación apical del ventrículo derecho
- 6085-510 - Experiencia de nuestro centro en el campo de la ablación de venas pulmonares con electroporación durante el último año. Análisis de tiempos de procedimiento, tasa de complicaciones y eficacia frente a los métodos actuales
- 5004-5 - Experiencia inicial de nuestro centro en la ablación del istmo mitral mediante electroporación para el abordaje de la fibrilación auricular
- 6075-469 - Rendimiento de sistemas de chat alimentados con artículos de investigación en un entorno clínico específico: la enfermedad valvular cardiaca